
|
LISA: Unsupervised Word-level Knowledge Graph-based Lexical Sentiment Analysis
| Mireille Fares1, Angela Moufarrej1, Eliane Jreij1, Joe Tekli1*, and William Grosky2
Department of Electrical and Computer Engineering, Lebanese American University (LAU), Byblos, Lebanon * This study was partly completed during the author's Fulbright Visiting Scholar research mission in the Computer and Information Science department, University of Michigan (UMich), Dearborn, USA |
| mireille.fares@lau.edu, angela.moufarrej@lau.edu, eliane.jreij@lau.edu, joe.tekli@lau.edu.lb, wgrosky@umich.edu |
I. Introduction
L exical s entiment a nalysis (or LSA) systems are automated tools which analyze words and text extracts provided by users, and attempt to classify them under different sentiment categories, such as: positive , negative , or neutral emotions. Affect analysis can be viewed as a more fine-grained approach of LSA, which involves more specific classes of affective emotions such as: happiness , sadness , surprise , and anger , etc. Most existing LSA approaches have utilized supervised learning techniques applied on corpus-based statistics in order to match words or textual patterns with sentiments represented as labeled categories, e.g., [1, 2, 3] . They usually require extensive training data, training time, and large statistical corpora which are not always available and require significant manual effort. In addition, most methods usually produce discrete sentiment labels (e.g., joy , surprise ) without however evaluating sentiment intensity (valence) scores (e.g., 20% joy , 35% surprise ). On the other hand, other studies have utilized unsupervised and lexicon-based approaches, e.g., [4, 5, 6] , in order to match target words with seed words in a sentiment lexicon (e.g., LEW list [7] , or WNA list [8] ), by evaluating their semantic similarity or distance in a reference lexical knowledge base (KB, e.g., WordNet [9] ). The latter usually suffer from the limited coverage of manually created sentiment lexicons, as well as the limited or inconsistent connectivity of affective concepts in the lexical KB. Recent efforts have focused on the automatic creation of sentiment corpora, e.g., [10, 11, 12] , in order to address some of the above limitations. Yet most rely on (semi)supervised processes for their construction, thus sharing the limitations of supervised method mentioned above. In this study, we introduce UWKG_LISA (or LISA for short), a framework for U nsupervised W ord-level K nowledge G raph-based L ex i cal S entiment A nalysis. In contrast with most existing supervised or corpus-based approaches, we provide an unsupervised knowledge-based solution which utilizes graph navigation techniques applied on a l exical- a ffective g raph (LAG), in order to infer word affect scores while avoiding the training data and training time bottlenecks. The LAG is created by connecting a typical lexical KB graph like WordNet, with a reliable affect KB like WordNet-Affect Hierarchy (WNAH) [13] (although any other lexical or affective KB sharing similar properties can be utilized).
II. System Architecture
The general architecture of our LISA is shown in Fig. 1. It was designed in two consecutive iterations, producing two main modules: i) LISA 1.0 for affect navigation, and ii) LISA 2.0 for affect propagation and lookup. LISA 1.0 accepts as input a set of user input words (e.g., extracted from a sentence) and a set of target affect categories in a LAG, and produces as output the target affect scores (intensity weights) for every input word located in the LAG. It consists of two main components: i) linguistic pre-processing , to process input words, identifying their proper word concepts (synsets) in the lexical KB graph (e.g., WordNet), and ii) Max_Affect which navigates the LAG from the input word concepts to the target affect categories, using an adaptation of the shortest path problem in order to identify the maximum word affect scores. Yet, preliminary experiments and a careful analysis of LISA 1.0 highlighted two main issues regarding the module's effectiveness and efficiency. On the one hand, we realized that the semantic connectivity between affect concepts in the LAG does not always accurately portray their affective expressiveness (e.g., concepts good and bad are only three hops away from each other in WordNet, despite their opposing sentiments, cf. Fig. 1 in Section 2.5 ), which reduced the module's accuracy in computing affect scores. On the other hand, LISA 1.0's main Max_Affect process requires average polynomial (quadratic) complexity in the size of the LAG, which, despite LAG navigation optimizations and parallelization, remained relatively time consuming.
This led us to improve our design by producing LISA 2.0, which first i) propagates the sentiment scores over all connected word concepts in the LAG, from a set of user target affect categories (target emotions), and then ii) allows fast lookups of the computed word affect scores to perform LSA. It encompasses three main components: i) WNAH_Propagation which propagates the affect score of every affect category in WNAH, to all other affect categories in WNAH, such that each category becomes fully representative of all of the others (only affective connections are considered here, to solve the LAG semantic connectivity problem of LISA 1.0), ii) Back_Propagation which backward propagates the affect scores, from user chosen affect categories (pre-processed by WNAH_Propagation ) to all connected concepts in the LAG. The set of affect-scored concepts form a sentiment lexicon which is utilized by iii) Affect_Lookup to perform fast search/lookup operations to identify word affect scores (requiring average logarithmic time, thus alleviating the polynomial complexity problem of LISA 1.0).
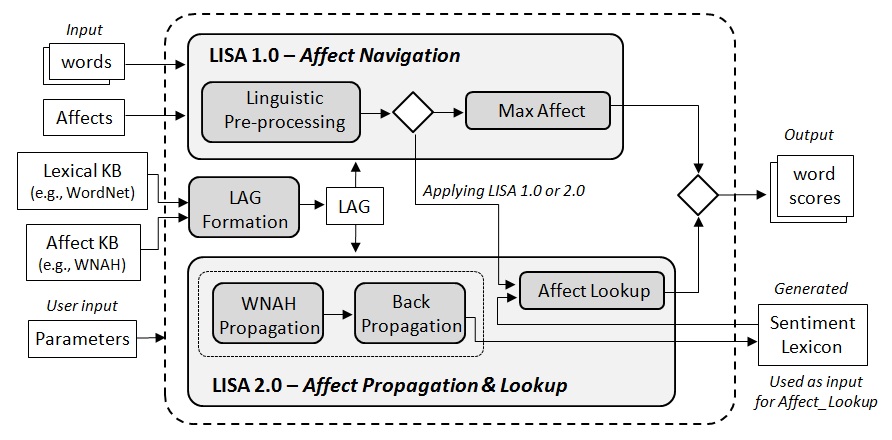 |
| Fig. 1. Overall LISA architecture |
III. Implementation and Tests
We have implemented LISA 1.0 and 2.0 to test and evaluate their performance. Experimental results on the Affective Norms for English Words (ANEW) dataset [14, 15] show that our approach, namely LISA 2.0, while completely unsupervised, is on a par with existing (semi)supervised solutions, highlighting its quality and potential.
The prototype system, experimental data and results can be downloaded from the following links:
Acknowledgments
This study is partly funded by the National Council for Scientific Research - Lebanon (CNRS-L), by the Lebanese American University (LAU), as well as the Fulbright Visiting Scholar program (sponsored by the US Department of State). Special thanks go to LAU computer engineering graduates Ms. Souad Charafeddine and Mr. Ralph Abboud who partly contributed to LISA's implementation.
Acknowledgments