
|
CFE - Category-based Feature Engineering for Improved Text Classification
| Joseph Attieh and Joe Tekli |
| SOE, Dept. of Electrical & Computer Eng. Lebanese American University 36 Byblos, Lebanon |
| joseph.attieh@lau.edu, joe.tekli@lau.edu.lb |
I. Introduction
With the rapid growth of online information, text classification (also known as text categorization or text labelling) has become a central task in Natural Language Processing (NLP), and has been widely studied in many application domains ranging over information retrieval, information filtering, and sentiment analysis.
Text classification consists of two main phases: i) feature representation phase, and ii) classification phase. State of the art text feature representations mainly rely on a weighted representation of the terms in the target documents. The underlying idea is that terms that are more important in describing a given document are assigned a higher weight. The weighted document representations are then run through a trained classifier to categorize the documents against a set of target classes or categories. Hence, choosing a suitable method for term weighting is of major importance and can have a big impact on the effectiveness of the classification task. Here, we distinguish between two kinds of weighting schemes: i) unsupervised, where the document representations rely solely on the distribution of the terms across the input documents, and ii) supervised, where document representations are augmented with knowledge regarding the target categories.
II. System Architecture
In this study, we introduce a new text classification framework for Category-based Feature Engineering titled CFE, which aims to improve classification quality by integrating term-category relationships in document and category representations (cf. Figure 1). Our solution consists of a supervised weighting scheme based on a variant of the TF-ICF (Term Frequency-Inverse Category Frequency) model [1]. Different from existing approaches which are designed for document representation, e.g., [2, 3, 4], we adapt TF-ICF to produce weighted representations for the target categories. We then embed the new weighting scheme in three novel text classification approaches: i) the main IterativeAdditive approach, and two neural variants: ii) GradientDescentANN, and iii) FeedForwardANN. The IterativeAdditive approach augments each document representation with a set of synthetic features inferred from the TF-ICF category representations. It builds a term-category TF-ICF matrix using an iterative and additive algorithm that produces category vector representations and updates until reaching convergence. GradientDescentANN replaces the iterative additive process mentioned previously by computing the term-category matrix using a gradient descent ANN model. Training the ANN using the gradient descent algorithm allows updating the term-category matrix until reaching convergence. FeedForwardANN uses a feed-forward ANN model to transform the document representations into the category vector space. The transformed document vectors are then compared with the target category vectors using cosine similarity in order to associate them with their most similar categories. We have implemented the CFE framework including its three classification approaches (cf. Figure 1), and we have conducted a large battery of tests to evaluate their performance. Experimental results on four benchmark datasets show that our approaches are on a par with and mostly improve text classification accuracy, compared with their recent alternatives.
 |
| Fig. 1. Overall CFE architecture |
II. A. Architecture of IterativeAdditive approach
The overall architecture of IterativeAdditive is shown in Figure 2. First, the term-category relationships are represented through two matrices computed using the term-category matrix computation module. The first matrix is populated with the vector weights of our TF-ICF variant The second matrix consists of a dynamic version of the first matrix that is iteratively updated to better fit the document dataset. It computes the relationships between terms and categories with respect to the feature search problem. The outcome of this step is two term-category matrices where every entry represents the importance of a term in describing a category. Once the term-category matrices are computed, aggregate features are extracted using the feature extraction module and are appended to the document representations. These augmented document representations are then used to train the classifier module . In our study, we adopt Support Vector Machine (SVM) as CFE's baseline classifier module, yet other classifiers can be used following the system designer's needs.
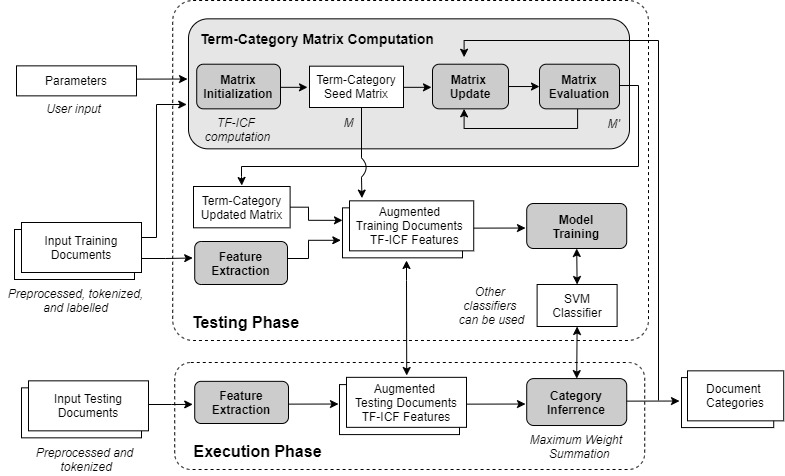 |
| Fig. 2. Overall IterativeAdditive architecture |
II. B. Architecture of GradientDescentANN approach
While IterativeAdditive adopts an iterative and additive approach to perform TF-ICF matrix computation, nonetheless, this process can be handled using other optimization solutions such as gradient descent or evolutionary-developmental algorithms. To showcase the extensibility of our approach, we introduce GradientDescentANN which computes the term-category weight matrix using a 1-layer ANN, where the inputs correspond to the terms in the vocabulary, and the outputs correspond to the predefined categories. The overall architecture of GradientDescentANN is shown in Figure 3. We adopt here a 1-layered ANN as the simplest possible solution to the problem, yet deeper neural structures can be considered. We utilize softmax as the activation function of the final layer (i.e., the only layer in our current 1-layered network), which is suitable with our decision function (i.e., the category with the highest weight in the output determines the category of the document). As a result, training the ANN using the gradient descent algorithm allows updating matrix M in order to satisfy our problem formulation.
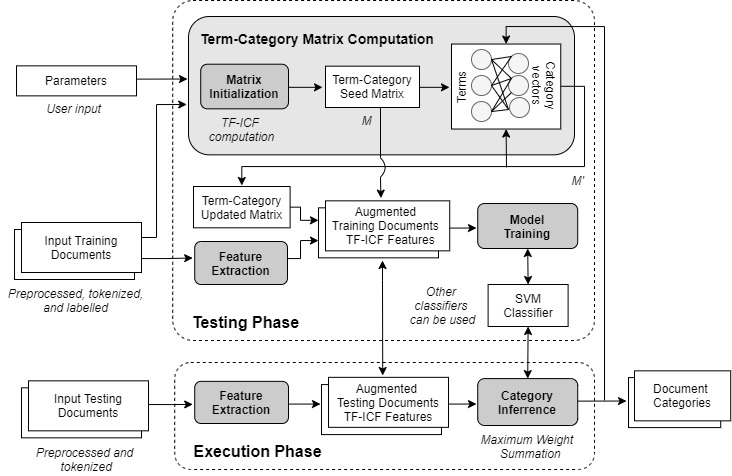 |
| Fig. 3. Overall GradientDescentANN architecture |
II. C. Architecture of FeedForwardANN approach
Our second neural variant, titled FeedForwardANN uses a feed-forward ANN to transform input document representations into the category feature space, where document vector representations from the same category are highly correlated and similar to their category vectors. The transformed document vectors are then compared with the target category vectors using cosine similarity for model training and categorization, in order to associate the input documents with their most similar categories. The overall architecture of FeedForwardANN is shown in Figure 4.
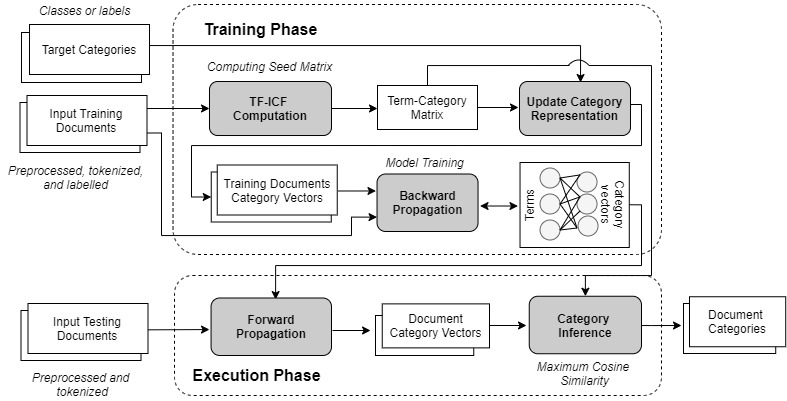 |
| Fig. 4. Overall FeedForwardANN architecture |
III. Implementation and Tests
We have implemented our CFE framework and its three classification solutions to test and evaluate their performance, and compare them with recent alternatives in the literature. Written in Python, our implementation comprises CFE's main modules and components, in addition to a linguistic pre-processing component to perform tokenization, stop word removal, and stemming. The prototype source code and experimental results can be downloaded from the following links:
References